Beamforming¶
Acoustic beamforming can strengthen a signal propagating from a particular direction or position and suppress interfering signals [VSR13] [WM09] [TRE02]. Such beamformers can be quickly implemented with BTK.
Fig. 2 illustrates a dependency graph of the feature pointer objects for building a beamformer. As shown in Fig. 2, we create multiple spectral objects, OverSampledDFTAnalysisBankPtr(), from the multi-channel audio signal and then feed them into the beamformer object, SubbandGSCPtr(). The beamformed subband component will be transformed back into the time domain through the OverSampledDFTSynthesisBankPtr().
We can easily try a different beamforming algorithm by replacing the beamforming object or cascade various processing methods by inserting before/after the beamformer process.
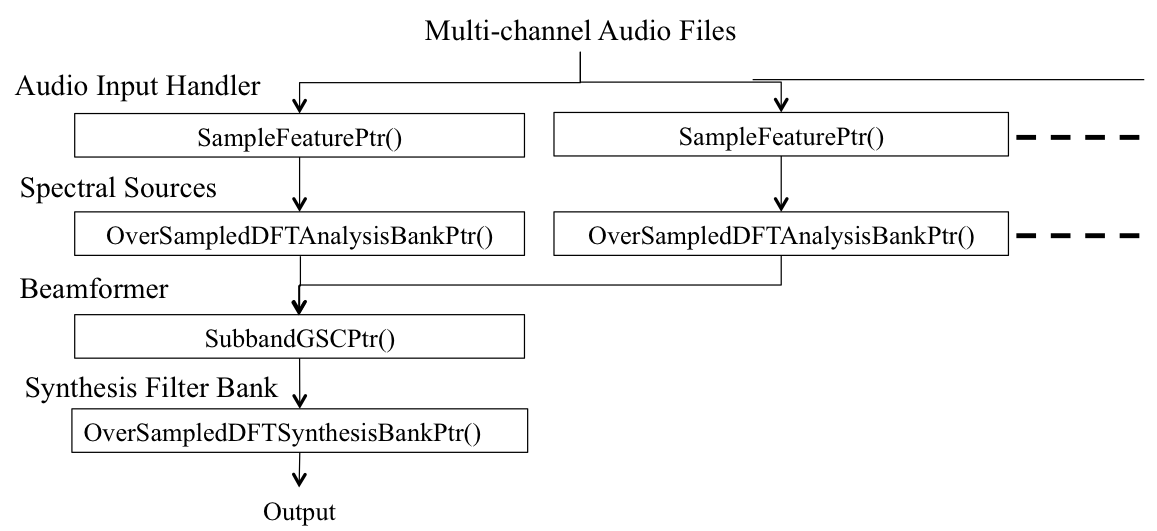
Object dependency for subband beamforming
The basic type of beamforming algorithms would be a data-independent method such as delay-and-sum (D&S) and super-directive (SD) beamformers [BS01]. The data-independent beamformers use the theoretical noise coherence model.
You may sometimes want to adapt a beamformer to a specific acoustic environment with a few observations. Adapting the beamformer with a few amount of data is cheaper than building multiple beamformers with a large amount of data. As you can imagine, there are many publications that claim to describe a new noise suppression algorithm. In terms of a necessary amount of adaptation data in running time, the beamforming techniques can be classified into two types of algorithms:
- Online processing that outputs a processed signal on a sample-by-sample or block-by-block basis in real time, and
- Batch processing that requires one utterance, typically 2 or more seconds, to capture enough statistics of the signal.
Listing 4 shows a sample python script that runs online beamforming algorithms. Delay-and-sum (D&S), super-directive (SD), linear constrained minimum variance (LCMV), generalized sidelobe canceller (GSC) recursive least squares (RLS) and GSC least mean-square (LMS) beamformers can fall into this class of algorithms.
In the case that the positions of sound sources do not change, we would rather use a more amount of stationary data for weight estimation than update it sample-by-sample quickly. That can be, for instance, done with a minimum variance distortionless response (MVDR) or generalized eigenvector (GEV) beamformer. BTK also provides such beamforming methods in unit_test/test_sos_batch_beamforming.
The beamforming techniques mentioned above only use second order statistics (SOS) of the signal. It is well-known that the distribution of the clean speech signal cannot be represented only with the SOS [KMB12]. Speech enhancement performance can be further improved by incorporating higher-order statistics (HOS) into beamforming. It is also implemented in BTK. Both SOS and HOS beamforming algorithms can co-exist under the GSC framework.
The spherical array is another interesting beamforming topic because of the elegant closed form solution in the spherical harmonics domain [ME04]. Spherical harmonics beamforming techniques would be suitable for three dimensional sound field reconstruction. Obviously, the beamforming performance will not be affected with respect to a direction of arrival in contrast to the linear array [KMB12]. The spherical harmonics beamformers are also implemented.
Note
The acoustic beamforming techniques will require prior knowledge: 1) geometric information or 2) sound source activity indicator. In the examples below, such information is specified in a JSON configuration file. The methods to estimate such information will be described later. The use of prior knowledge indeed distinguishes acoustic beamforming from blind source separation techniques that can be unstable in the case that a limited amount of adaptation or training data is only available.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 | #!/usr/bin/python
"""
Test online subband beamforming algorithms that can update weights online (as opposed to batch processing)
.. reference::
.. moduleauthor:: John McDonough, Kenichi Kumatani <k_kumatani@ieee.org>
"""
import argparse, json
import os.path
import pickle
import wave
import sys
import numpy
from btk20.common import *
from btk20.stream import *
from btk20.feature import *
from btk20.modulated import *
from btk20.beamformer import *
from btk20.pybeamformer import *
from btk20.postfilter import *
SSPEED = 343740.0
def check_position_data_format(ap_conf):
"""
Check the following items in position information:
- if the dimension of the postion vector is sufficient, and
- if time stamp matches between target and noise sources,
"""
def check_position_dim(t, pos):
if ap_conf['array_type'] == 'linear':
assert len(pos) >= 1, 'Insufficient position info. at time %0.3f' %t
elif ap_conf['array_type'] == 'planar' or ap_conf['array_type'] == 'circular':
assert len(pos) >= 2, 'Insufficient position info. at time %0.3f' %t
else:
assert len(pos) >= 3, 'Insufficient position info. at time %0.3f' %t
assert 'positions' in ap_conf['target'], 'No target position'
for posx, (targ_t, pos) in enumerate(ap_conf['target']['positions']):
check_position_dim(targ_t, pos)
if 'noises' in ap_conf:
for noisex in range(len(ap_conf['noises'])):
noise_t = ap_conf['noises'][noisex]['positions'][posx][0]
assert targ_t == noise_t, "%d-th noise: Misaligned time stamp %0.4f != %0.4f" %(noisex, targ_t, noise_t)
check_position_dim(noise_t, ap_conf['noises'][noisex]['positions'][posx][1])
def online_beamforming(h_fb, g_fb, D, M, m, r, input_audio_paths, out_path, ap_conf, samplerate):
"""
Run a class of online beamforming algorithms
:param h_fb: Analysis filter coefficeint; This must be generated with /tools/filterbank/{design_nyquist_filter.py,design_de_haan_filter.py}
:type h_fb: numpy float vector
:param g_fb: Synthesis filter coefficients paird with h_fb
:type g_fbM: numpy float vector
:param M: Number of subbands
:type M: integer
:param m: Filter length factor
:type m: integer
:param D: Decimation factor
:type D: integer
:param input_audio_path: List of input audio file that you would like to dereverb
:type input_audio_path: List of string
:param out_path: Output audio file
:type out_path: string
:param ap_conf: Dictionary to specify beamforming parameters
:type ap_conf: Python dictionary
:param samplerate: Sampling rate of the input audio
:type samplerate: integer
:returns: Tuple of total beamformer's output power and the number of processed frames
"""
channels_num = len(input_audio_paths)
sample_feats = []
afbs = []
for c, input_audio_path in enumerate(input_audio_paths):
# Instantiation of an audio file reader
sample_feat = SampleFeaturePtr(block_len = D, shift_len = D, pad_zeros = True)
sample_feat.read(input_audio_path, samplerate)
# Instantiation of over-sampled DFT analysis filter bank
afb = OverSampledDFTAnalysisBankPtr(sample_feat, prototype = h_fb, M = M, m = m, r = r, delay_compensation_type=2)
# Keep the instances
sample_feats.append(sample_feat)
afbs.append(afb)
# Setting a beamformer
bf_conf = ap_conf['beamformer']
if bf_conf['type'] == 'delay_and_sum' :
beamformer = SubbandGSCBeamformer(afbs, Nc = 1)
elif bf_conf['type'] == 'lcmv':
beamformer = SubbandGSCBeamformer(afbs, Nc = 2)
elif bf_conf['type'] == 'super_directive':
beamformer = SubbandMVDRBeamformer(afbs)
elif bf_conf['type'] == 'gsclms':
beamformer = SubbandGSCLMSBeamformer(afbs,
beta = bf_conf.get('beta', 0.97), # forgetting factor for recursive signal power est.
gamma = bf_conf.get('gamma', 0.01), # step size factor
init_diagonal_load = bf_conf.get('init_diagonal_load', 1.0E+6), # represent each subband energy
energy_floor = bf_conf.get('energy_floor', 90), # flooring small energy
sil_thresh = bf_conf.get('sil_thresh', 1.0E+8), # silence threshold
max_wa_l2norm = bf_conf.get('max_wa_l2norm', 100.0)) # Threshold so |wa|^2 <= max_wa_l2nor
elif bf_conf['type'] == 'gscrls':
beamformer = SubbandGSCRLSBeamformer(afbs,
beta = bf_conf.get('beta', 0.97), # forgetting factor for recursive signal power est.
gamma = bf_conf.get('gamma', 0.1), # step size factor
mu = bf_conf.get('mu', 0.97), # recursive weight for covariance matrix est.
init_diagonal_load = bf_conf.get('init_diagonal_load', 1.0E+6),
fixed_diagonal_load = bf_conf.get('fixed_diagonal_load', 0.01),
sil_thresh = bf_conf.get('sil_thresh', 1.0E+8),
constraint_option = bf_conf.get('constraint_option', 3), # Constrait method for active weight vector est.
alpha2 = bf_conf.get('alpha2', 10.0), # 1st threshold so |wa|^2 <= alpha2
max_wa_l2norm = bf_conf.get('max_wa_l2norm', 100.0)) # 2nd threshold so |wa|^2 <= max_wa_l2norm
else:
raise KeyError('Invalid beamformer type: {}'.format(bf_conf['type']))
# Setting a post-filter
use_postfilter = False
pybeamformer = PyVectorComplexFeatureStreamPtr(beamformer) # convert a pure python class into BTK stream object
if not ('postfilter' in ap_conf):
spatial_filter = pybeamformer
elif bf_conf['type'] == 'delay_and_sum' or bf_conf['type'] == 'lcmv' or bf_conf['type'] == 'super_directive':
pf_conf = ap_conf['postfilter']
if pf_conf['type'] == 'zelinski':
spatial_filter = ZelinskiPostFilterPtr(pybeamformer, M,
pf_conf.get('alpha', 0.6),
pf_conf.get('subtype', 2))
elif pf_conf['type'] == 'mccowan':
spatial_filter = McCowanPostFilterPtr(pybeamformer, M,
pf_conf.get('alpha', 0.6),
pf_conf.get('subtype', 2))
spatial_filter.set_diffuse_noise_model(ap_conf['microphone_positions'], samplerate, SSPEED)
spatial_filter.set_all_diagonal_loading(bf_conf.get('diagonal_load', 0.01))
elif pf_conf['type'] == 'lefkimmiatis':
spatial_filter = LefkimmiatisPostFilterPtr(pybeamformer, M,
pf_conf.get('min_sv', 1e-8),
pf_conf.get('fbin_no1', 128),
pf_conf.get('alpha', 0.8),
pf_conf.get('subtype', 2))
spatial_filter.set_diffuse_noise_model(ap_conf['microphone_positions'], samplerate, SSPEED)
spatial_filter.set_all_diagonal_loading(bf_conf.get('diagonal_load', 0.1))
spatial_filter.calc_inverse_noise_spatial_spectral_matrix()
else:
raise KeyError('Invalid post-filter type: {}'.format(pf_conf['type']))
use_postfilter = True
else:
raise NotImplementedError("Post-filter unsupported: {}".format(bf_conf['type']))
# Setting the beamformer / post-filter instance to the synthesis filter bank
sfb = OverSampledDFTSynthesisBankPtr(spatial_filter, prototype = g_fb, M = M, m = m, r = r, delay_compensation_type = 2)
# Open an output file pointer
wavefile = wave.open(out_path, 'w')
wavefile.setnchannels(1)
wavefile.setsampwidth(2)
wavefile.setframerate(int(samplerate))
def wrapper_weights_calculator(delays_t, delays_js=None):
"""
wrapping the functions for beamformer weight computation
"""
if delays_js is not None and bf_conf['type'] != 'lcmv':
print('Noise information will be ignored')
if bf_conf['type'] == 'delay_and_sum':
beamformer.calc_beamformer_weights(samplerate, delays_t)
elif bf_conf['type'] == 'super_directive':
beamformer.calc_sd_beamformer_weights(samplerate, delays_t,
ap_conf['microphone_positions'], sspeed = SSPEED,
mu = bf_conf.get('diagonal_load', 0.01))
elif bf_conf['type'] == 'gsclms' or bf_conf['type'] == 'gscrls':
beamformer.calc_beamformer_weights(samplerate, delays_t)
elif bf_conf['type'] == 'lcmv': # put multiple linear constraints (distortionless and null)
assert delays_js is not None, 'LCMV beamforming: missing noise source positions'
beamformer.calc_beamformer_weights_n(samplerate, delays_t, delays_js)
# Perform beamforming
total_energy = 0
elapsed_time = 0.0
time_delta = D / float(samplerate)
# Set the initial look direction(s)
posx = 0
# Direction of the target souce
target_position_t = ap_conf['target']['positions'][posx][1]
delays_t = calc_delays(ap_conf['array_type'], ap_conf['microphone_positions'], target_position_t, sspeed = SSPEED)
delays_js = None
if 'noises' in ap_conf: # Direction of jammer(s)
delays_js = numpy.zeros((len(ap_conf['noises']), len(delays_t)), numpy.float) # (no. noises) x (no. mics) matrix
for noisex in range(len(delays_js)):
noise_position_t = ap_conf['noises'][noisex]['positions'][posx][1]
delays_js[noisex] = calc_delays(ap_conf['array_type'], ap_conf['microphone_positions'], noise_position_t, sspeed = SSPEED)
# Compute the initial beamformer weight
wrapper_weights_calculator(delays_t, delays_js)
if use_postfilter == True:
spatial_filter.set_beamformer(beamformer.beamformer())
for frame_no, buf in enumerate(sfb):
total_energy += numpy.inner(buf, buf)
wavefile.writeframes(numpy.array(buf, numpy.int16).tostring())
elapsed_time += time_delta
if elapsed_time > ap_conf['target']['positions'][posx][0] and (posx + 1) < len(ap_conf['target']['positions']):
# Update the look direction(s)
posx += 1
target_position_t = ap_conf['target']['positions'][posx][1]
delays_t = calc_delays(ap_conf['array_type'], ap_conf['microphone_positions'], target_position_t, sspeed = SSPEED)
if 'noises' in ap_conf: # Direction of jammer(s)
delays_js = numpy.zeros((len(ap_conf['noises']), len(delays_t)), numpy.float) # (no. noises) x (no. mics) matrix
for noisex in range(len(delays_js)):
noise_position_t = ap_conf['noises'][noisex]['positions'][posx][1]
delays_js[noisex] = calc_delays(ap_conf['array_type'], ap_conf['microphone_positions'], noise_position_t, sspeed = SSPEED)
# Recompute the beamformer weight
wrapper_weights_calculator(delays_t, delays_js)
# Close all the output file pointers
wavefile.close()
return (total_energy, frame_no)
def test_online_beamforming(analysis_filter_path,
synthesis_filter_path,
M, m, r,
input_audio_paths,
out_path,
ap_conf,
samplerate=16000):
D = M / 2**r # frame shift
# Read analysis prototype 'h'
with open(analysis_filter_path, 'r') as fp:
h_fb = pickle.load(fp)
# Read synthesis prototype 'g'
with open(synthesis_filter_path, 'r') as fp:
g_fb = pickle.load(fp)
if not os.path.exists(os.path.dirname(out_path)):
try:
os.makedirs(os.path.dirname(out_path))
except:
pass
return online_beamforming(h_fb, g_fb, D, M, m, r, input_audio_paths, out_path, ap_conf, samplerate)
def build_parser():
M = 256
m = 4
r = 1
protoPath = 'prototype.ny'
analysis_filter_path = '%s/h-M%d-m%d-r%d.pickle' %(protoPath, M, m, r)
synthesis_filter_path = '%s/g-M%d-m%d-r%d.pickle' %(protoPath, M, m, r)
default_input_audio_paths = ['data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav',
'data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav',
'data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav',
'data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav']
default_out_path = 'out/U1001_1M_beamformed.wav'
parser = argparse.ArgumentParser(description='test subband WPE dereverberation.')
parser.add_argument('-a', dest='analysis_filter_path',
default=analysis_filter_path,
help='analysis filter prototype file')
parser.add_argument('-s', dest='synthesis_filter_path',
default=synthesis_filter_path,
help='synthesis filter prototype file')
parser.add_argument('-M', dest='M',
default=M, type=int,
help='no. of subbands')
parser.add_argument('-m', dest='m',
default=m, type=int,
help='Prototype filter length factor')
parser.add_argument('-r', dest='r',
default=r, type=int,
help='Decimation factor')
parser.add_argument('-i', dest='input_audio_paths', nargs='+',
default=default_input_audio_paths,
help='observation audio file(s)')
parser.add_argument('-o', dest='out_path',
default=default_out_path,
help='output audio file')
parser.add_argument('-c', dest='ap_conf_path',
default=None,
help='JSON path for array processing configuration')
return parser
if __name__ == '__main__':
parser = build_parser()
args = parser.parse_args()
if args.ap_conf_path is None:
# Default arrayp processing configuration
ap_conf={'array_type':'linear', # 'linear', 'planar', 'circular' or 'nearfield'
'microphone_positions':[[-113.0, 0.0, 2.0],
[ 36.0, 0.0, 2.0],
[ 76.0, 0.0, 2.0],
[ 113.0, 0.0, 2.0]],
'target':{'positions':[[0.0, [-1.306379, None, None]]]}, # [time, [position vector]], if 'linear', the position value is the direction of arrival in radian.
'beamformer':{'type':'super_directive'}, # 'delay_and_sum' 'gsclms' or 'gscrls'
'postfilter':{'type':'zelinski',
'subtype':2,
'alpha':0.7}
}
else:
with open(args.ap_conf_path, 'r') as jsonfp:
ap_conf = json.load(jsonfp)
print('BF config.')
check_position_data_format(ap_conf)
print(json.dumps(ap_conf, indent=4))
print('')
(total_energy, frame_no) = test_online_beamforming(args.analysis_filter_path,
args.synthesis_filter_path,
args.M, args.m, args.r,
args.input_audio_paths,
args.out_path,
ap_conf,
samplerate=16000)
print('Avg. output power: %f' %(total_energy / frame_no))
print('No. frames processed: %d' %frame_no)
|
Data Independent Beamforming¶
Delay-and-sum (D&S) Beamforming¶
The D&S beamformer is implemented as one of options in “unit_test/test_online_beamforming”. To try D&S beamforming only, run that script in your Git repository as
$ cd ${YOUR_GIT_REPOSITORY}/unit_test
$ python test_online_beamforming.py \
-c confs/ds.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_ds.wav
This will generate a beamformed audio file as out/U1001_1M_ds.wav.
Super-Directive Beamforming¶
The super-directive beamforming [BS01] is optimum for the spherically isotropic (diffuse) noise field. It can be also viewed as a special case of minimum variance distortionless beamforming where the noise coherence matrix is fixed.
SD beamforming can be done by giving the “unit_test/confs/sd.json” JSON to the “unit_test/test_online_beamforming” Python script as
$ cd ${YOUR_GIT_REPOSITORY}/unit_test
$ python test_online_beamforming.py \
-c confs/sd.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_sd.wav
Here, the JSON file for SD beamforming looks:
$ cat confs/sd.json
{"array_type":"linear",
"microphone_positions":[[-113.0, 0.0, 2.0],
[ 36.0, 0.0, 2.0],
[ 76.0, 0.0, 2.0],
[ 113.0, 0.0, 2.0]],
"target":{"positions":[[0.0, [-1.306379, null, null]]]},
"beamformer":{"type":"super_directive", "diagonal_load":0.01}
}
Tip
You can adjust white noise gain by changing an amount of diagonal loading, specified with [“beamformer”][“diagonal_load”] in the JSON file or at line 172 in Listing 4. The smaller diagonal loading value indicates a sharper directivity but less white noise gain.
LCMV beamforming¶
Beamforming can also place null on a signal coming from a particular direction. It is sometimes called null-steering beamforming. The linear constrained minimum variance (LCMV) beamformer can be viewed as a general form of delay-and-sum and null-steering beamformers. By specifying the direction of each sound source, the LCMV beamformer can strengthen or null out the source.
The following command will do LCMV beamforming.
$ cd ${YOUR_GIT_REPOSITORY}/unit_test
$ python test_online_beamforming.py \
-c confs/lcmv_and_zelinski.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_lcmvz.wav
Compare the input file with the output file to see that the LCMV beamformer can weaken the signal.
SOS Adaptive Beamforming¶
Tip
We would recommend you read Chapter 6 and 7 in [TRE02] if you don’t do so. Once you go through the book [TRE02], you will find many recent publications on adaptive beamforming and source separation techniques merely describe a variant of the methods explained in [TRE02]. Many algorithms address how to estimate an optimal weight with a small amount of adaptation data based on the second order statistics (SOS).
Among hundreds of SOS-based beamforming, BTK provides four representative beamformers as follows.
GSC RLS Beamforming¶
There was a great deal of attention paid to research on recursive weight update algorithms for adaptive filtering instead of batch update. The recursive implementation is suitable for real-time processing. The BTK provides a generalized sidelobe canceller recursive least squares (GSC-RLS) beamformer with quadratic constraints; see section 4.4 in [TRE02] for the detail.
You can test GSC-RLS beamforming by running “unit_test/test_online_beamforming” with “unit_test/confs/gscrls.json”:
$ cd ${YOUR_GIT_REPOSITORY}/unit_test
$ python test_online_beamforming.py \
-c confs/gscrls.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_gscrls.wav
The GSC-RLS beamformer actually has hyper-parameters to be tuned for stabilizing active weight estimation. Table 1 lists the hyper-parameters for GSC-RLS beamforming.
| Hyperparameter | What is this? |
|---|---|
| beta | Forgetting factor to Smooth an power estimate |
| gamma | Step size factor to control a speed of weight estimation |
| mu | Forgetting factor to forget observations in the past |
| init_diagonal_load | Initial value for the power estimate |
| regularization_param | Parameter to regularize the large weight vector value |
| sil_thresh | Silence power threshold used for determining whether the weight vector is updated or not |
| constraint_option | Constraint option for weight estimation: 1. Quadratic constraint, 2. Weight vector norm normalization 3. Hybrid of two methods |
| alpha2 | Quadratic constraint so as to keep |wa|^2 <= alpha2 |
| max_wa_l2norm | Norm normalization parameter to limit the vector norm: |wa|^2 == max_wa_l2norm |
| min_frames | Start updating weights after “min_frames” observations |
| slowdown_after | Decrease a step size after “slowdown_after” frames |
GSC LMS Beamforming¶
The least mean square (LMS) is a stochastic version of the steepest algorithm. The computational cost of the LMS beamformers would be less expensive than that of the RLS implementation due to no need of Kalman gain computation for the inverse of a sample spectral matrix. However, the convergence speed of the LMS beamformers will depend on the eigenvalue spread.
The BTK implements the power normalized LMS (PN-LMS) beamformer configured in GSC [TRE02]. In the same way as described above, run “unit_test/test_online_beamforming” but with a JSON configuration file “unit_test/confs/gsclms.json”:
$ python test_online_beamforming.py \
-c confs/gsclms.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_gsclms.wav
The convergence performance of the LMS beamformer is also very sensitive to a rapid acoustic change. Table 2 shows the hyper-parameters to control an adaptation speed, leakage degree and regularization term.
| Hyperparameter | What is this? |
|---|---|
| beta | Forgetting factor to Smooth an power estimate |
| gamma | Step size factor to control a speed of weight estimation |
| init_diagonal_load | Initial value for the power estimate |
| regularization_param | Leak amount to avoid a large weight change |
| energy_floor | Value to floor the small signal energy |
| sil_thresh | Silence power threshold used for determining whether the weight vector is updated or not |
| max_wa_l2norm | Norm normalization parameter to limit the vector norm: |wa|^2 == max_wa_l2norm |
| min_frames | Start updating weights after “min_frames” observations |
| slowdown_after | Decrease a step size after “slowdown_after” frames |
MVDR Beamforming with Sample Matrix Inversion (SMI)¶
The BTK provides two popular MVDR beamforming implementations: the sighted and blind MVDR beamformers [SBA10]. You can try those beamformers with unit_test/test_sos_batch_beamforming. Each method requires a different kind of prior knowledge. The location of the target source has to be given to the sighted MVDR beamformer while the blind MVDR implementation does not require the look directions. In general, blind beamforming algorithms will need more precise speech and noise segmentation information. Such information can be specified in a JSON configuration file for unit_test/test_sos_batch_beamforming. Let us take a look at both cases.
Clear-sighted approach¶
For the sighted MVDR beamformer, you will need to specify a position estimate and speech activity segment in a JSON form as
$ cd ${YOUR_GIT_REPOSITORY}/unit_test
$ cat confs/smimvdr.json
{"array_type":"linear",
"microphone_positions":[[-113.0, 0.0, 2.0],
[ 36.0, 0.0, 2.0],
[ 76.0, 0.0, 2.0],
[ 113.0, 0.0, 2.0]],
"target":{"positions":[[0.0, [-1.306379, null, null]]],
"vad_label":[[1.5, 4.0]]},
"beamformer":{"type":"smimvdr",
"mu":1e-4,
"energy_threshold":10}
}
As shown above, this JSON file has array geometry as well as the direction of the target source. It also specifies the start and end time of voice activity in the “vad_label” key. The noise covariance matrix will be computed from non-speech signals with the greater than “energy_threshold” energy. Diagonal loading will be performed for noise covariance matrix inversion by adding the value in the “mu” key. By feeding the JSON file above, you can run the MVDR beamformer as
$ cd ${your_Git_repository}/unit_test
$ python test_sos_batch_beamforming.py \
-c confs/smimvdr.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_smimvdr.wav
Blind approach¶
The MVDR criterion can be also achived without the look direction [SBA10]. This is also known as the minimum mean square error (MMSE) beamformer [TRE02]. For this, you will only need to specify the region of the target and noise signals as
$ cd ${your_Git_repository}/unit_test
$ cat confs/bmvdr_vad.json
{
"target":{"vad_label":[[1.5, 4.0]]},
"beamformer":{"type":"bmvdr",
"energy_threshold":10,
"ref_micx":0,
"offset":0.0}
}
Here, you can change the reference microphone index with the “ref_micx” value. With the “offset” value, you can adjust a SNR gain. Then, we can run the sample script with that JSON file as
$ python test_sos_batch_beamforming.py \
-c confs/bmvdr_vad.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_bmvdr_vad.wav
The VAD label described above does not contain source activity information for each frequency band. The straightforward idea is providing the beamformer with time-frequency (TF) masks which indicate subband activity of each sound source [HDH16]. We can do it by specifying the mask file paths to the target and noise sources as
$ cd ${your_Git_repository}/unit_test
$ cat confs/bmvdr_vad.json
{
"target":{"tfmask_path":"data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k.speech.tfmask.pickle"},
"noises":[{"tfmask_path":"data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k.noise.tfmask.pickle"}],
"beamformer":{"type":"bmvdr",
"energy_threshold":10,
"ref_micx":0,
"offset":0.0}
}
The Python pickle files specified in the “tfmask_path” key contain a sequence (number of frames) of mask value vectors for the target and noise sources. With this JSON file, we can run the blind MVDR beamformer as
$ python test_sos_batch_beamforming.py \
-c confs/bmvdr_tfmask.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_bmvdr_tfmask.wav
The example here actually provides an ideal mask computed from close-talking microphone data. The mask can be estimated through a neural network trained with a pair of the clean and artificially-corrupted data [HDH16] [HKIK+18]. You can, for example, use Paderborn University’s toolkit nn-gev.
Generalized Eigenvector (GEV) Beamforming¶
Another popular blind beamformer is generalized eigenvector (GEV) beamforming [WH07] [HDH16]. The GEV beamformer can be built in the same manner as the blind MVDR beamformer. The simpler way is just feeding a voice activity segment label without frequency information as
$ cd ${your_Git_repository}/unit_test
$ cat confs/gev_vad.json
{
"target":{"vad_label":[[1.5, 4.0]]},
"beamformer":{"type":"gev",
"energy_threshold":10}
}
And run the following command:
$ python test_sos_batch_beamforming.py \
-c confs/gev_vad.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_gev_vad.wav
Again, we can specify sound source activity per frequency bin in the same way as blind MVDR beamforming:
$ cd ${your_Git_repository}/unit_test
{
"target":{"tfmask_path":"data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k.speech.tfmask.pickle"},
"noises":[{"tfmask_path":"data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k.noise.tfmask.pickle"}],
"beamformer":{"type":"gev",
"energy_threshold":10}
}
And do TF mask-based beamforming as follows.
$ python test_sos_batch_beamforming.py \
-c confs/gev_tfmask.json \
-i data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c1.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c2.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c3.wav \
data/CMU/R1/M1005/KINECT/RAW/segmented/U1001_1M_16k_b16_c4.wav \
-o out/U1001_1M_gev_tfmask.wav
The GEV beamformer attempts at maximizing the output signal-to-noise ratio (SNR). You may feel GEV beamforming does not suppress noise as much as the other beamformers do. However, the target signal is emphasized.
Note
You will need to install scipy for The GEV beamformer.
Warning
The best case scenario for conventional adaptive beamformers is the static acoustic environment where both target and noise source positions are fixed and located at different positions. Adaptive beamforming may degrade speech recognition accuracy in complex acoustic environments in the case that either a speaker or noise source moves or sound presence timing varies because of steering errors [SU96].
HOS Adaptive Beamforming¶
In practice, these adaptive beamformers with the second-order statistics could suppress the desired signal as well as noise. The key technique for avoiding the signal cancellation effect would be
- Using a different criterion for optimization [KMB12],
- Locating a desired source position accurately or
- Estimating each source activity [HDH16] [HKIK+18].
This section describes a beamforming technique with the maximum super-Gaussian criterion, which turned out to be robust against the reverberation and beam steering error.